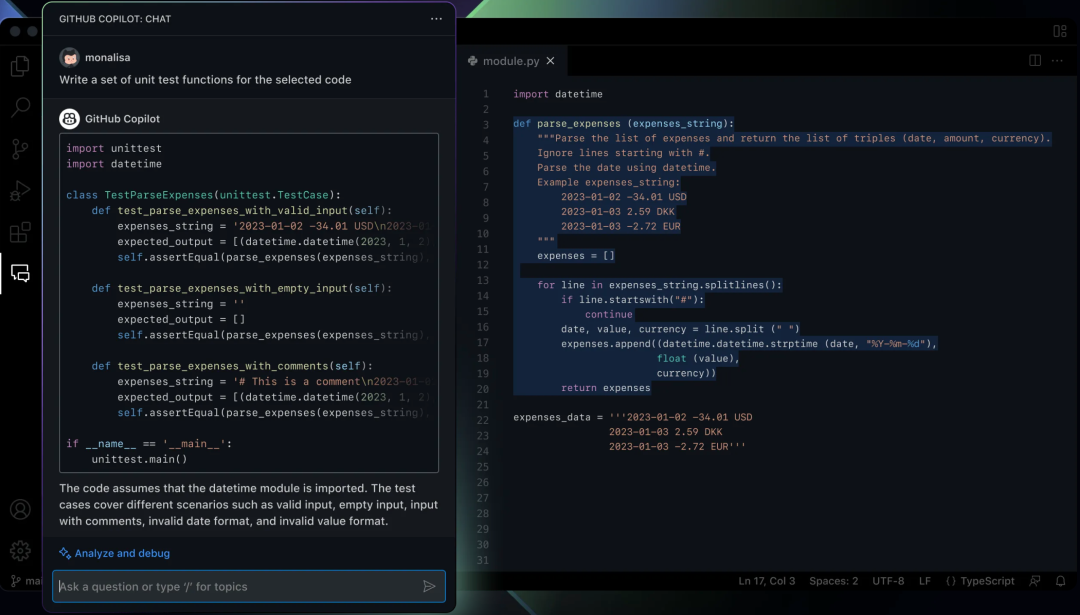
「高级请求次数」正在退场。2025 年 6 月,Cursor 把 Pro 从「每月 500 次请求」改成「含 $20 API 额度的 Token 账本」;2026 年 6 月 1 日,GitHub Copilot 全线从 Premium Request Units(PRU)切到 GitHub AI Credits,按 input / output / cached tokens 与模型牌价计费。两家产品的月费标价大多没变,但计量尺子彻底换了。
过去,一次 30 秒的问答和一次让 Agent 扫完整个 monorepo 的长会话,在「次数制」下可能只算 1 次高级请求;现在,后者可能吃掉你大半个月的 Credits。Cursor 官方曾直言:最难的请求,成本可达简单请求的约 10 倍。
这意味着:AI 编程的竞争,从「谁更会提问」升级为 「谁更会用更少的 Token,换更多的可合并交付」。本文简要回顾这场计费转变,然后给出中肯的省 Token 建议,以及如何构建一套可复用的 Token 产出比(Token ROI) 体系。
一、计费转变:你需要记住的几条事实
不必记全价目表,只需记住双轨结构——这是省 Token 的总前提。
| 产品 | 旧模式 | 新模式 | 仍「相对便宜」的轨道 |
| Cursor(2025-06 起) | 按请求次数(如 Pro 500 次/月) | 含 API 额度 + 按 Token 计价(Pro 含 $20) | Auto / Tab 等路径有单独策略;前沿模型按 Token 扣额度 |
| GitHub Copilot(2026-06-01 起) | PRU(高级请求次数) | AI Credits(Pro $10、Pro+ $39 等与月费对齐) | 代码补全、Next Edit 不消耗 Credits |
| 两者共性 | 一次一价,长短会话同价 | input + output + cache,模型越贵 multiplier 越高 | Agent、长对话、Code Review 等走 计量轨道 |
还有三点会直接影响你的策略:
- Copilot 取消 fallback:Credits 用尽后不再有低成本兜底模型,必须预算或封顶。
- Copilot Code Review 同时消耗 Credits + GitHub Actions 分钟——自动化审查也有双账单。
- 输出 Token 通常比输入更贵(多数模型 output 单价高于 input):让 AI 少废话、少重复贴大段代码,往往比少贴一点上下文更省钱。
计费转变的本质信号只有一句:补全 subsidized,推理 metered——机械写代码继续便宜,思考与代理开始按算力结账。省 Token 不是抠门,而是把资源投在真正产生交付的地方。
二、先定义「Token 产出比」,再谈技巧
很多人把 Token 省没省,等同于「对话轮数少不少」——这是错的。
Token 产出比 建议定义为:
可验证的有效交付 ÷ 消耗的 Token(或 Credits 折算)
其中「有效交付」必须是工程语言,而不是模型语言:
- ✅ 合并进主分支、通过 CI 的 PR
- ✅ 修复了具体 bug 或通过了具体测试
- ✅ 产出了可执行的方案,且经人工证伪后仍成立
- ❌ 生成了 2000 行未编译的代码
- ❌ 长文解释「应该如何架构」但无验收标准
- ❌ 同一错误在 5 轮对话里反复出现
高 Token 产出比 不是「问得少」,而是 「每一轮都缩小不确定性」。一次高质量、边界清晰的 Agent 任务,可能比十次模糊问答更省 Token——因为后者在重复烧 context,前者在收敛交付。
立意在这里:Token 时代,懒惰的 prompt 是最贵的 luxury。
六种最常见的 Token 浪费(对照自查)
| 浪费模式 | 典型表现 | 更省的做法 |
| 轨道错配 | 用 Agent 写单行补全、改 import | 交给 Tab / 补全 |
| 上下文通胀 | @ 整个仓库、贴无关 issue 长串 | 只贴目标片段 + 签名 |
| 模型过载 | 改 typo 也开 frontier 模型 | 日常档默认,复杂才升档 |
| 输出失控 | 第一轮就要「完整实现 + 全文解释」 | 先摘要确认,再生成补丁 |
| 会话拖尸 | 20 轮在同一错误上绕圈 | 达轮次上限 → 切片或新会话 |
| Review 滥用 | 每个 PR 自动 AI Review | 白名单路径 + 高风险变更 |
浪费往往不在「用 AI」,而在 「用错轨道、用错粒度、用错终止条件」。
三、个人层面:十条中肯的省 Token 建议
以下按「投入产出」排序,先做前四条,收益最大。
1. 双轨分流:补全写代码,Agent 做决策
能靠 Tab / 补全 / Next Edit 完成的,不要开 Agent。Copilot 已明确补全不走 Credits;Cursor 的 Tab 路径也相对独立。把 Agent 留给:跨文件、需要工具调用、需要多步推理的任务。
2. 先写验收标准,再开 Agent
没有 3–5 条验收条件就启动 Agent,等于付费让模型替你「猜需求」。在 prompt 里固定结构:目标 → 边界(不能改什么)→ 验收条件 → 输出格式。验收标准越硬,返工轮数越少,output Token 的浪费越少。
3. 任务切片,一次一个可验证闭环
「顺手重构 + 改 12 个文件 + 补测试」是 Token 黑洞。一次只做一个最小闭环:一个接口、一类错误处理、一个测试目标。闭环完成即 结束会话,避免在长 context 里累积垃圾信息。
4. 最小上下文,而非最大上下文
只贴:目标文件片段、相关签名、错误日志、约束规则。不要整库 @、不要贴无关 PR 历史。上下文每多 10KB,每一轮都在重复计费。边界清晰的 200 行,往往胜过模糊的 2000 行。
5. 模型分级:默认档解决 80%, frontier 解决 20%
最贵模型不是默认档。日常改 bug、写测试、改文档用中等模型;只有架构权衡、复杂并发、非常规调试才升档。Cursor 与 Copilot 均按模型价差计费——升档一次,整段会话的 multiplier 都在生效。
6. 控制输出形态:先要方案摘要,再要补丁
要求 AI 先给 5 点以内的方案摘要 + 风险,你确认后再生成代码。避免第一轮就输出数百行 diff,其中一半用不上。Output Token 贵,「先对齐再生成」 是最直接的省钱。
7. 新会话优于超长会话
对话超过 15–20 轮,或 context 已塞满历史试错,开新会话 + 用 10 行摘要交接,通常比继续追问更省。长会话里,早期无关内容会被反复带入后续每一轮计费。
8. 让 AI 自检,但限定自检格式
要求「对照验收条件逐条标 ✅/❌,不确定的假设列 3 条」,而不是「请全面 review 整个项目」。无边界自检会触发又一轮大 output。
9. 慎用「全自动 Review 一切 PR」
Copilot Code Review 吃 Credits 又吃 Actions 分钟。只对高风险变更(鉴权、计费、数据迁移)或核心模块启用;低风险 typo、文档 PR 人工扫一眼即可。
10. 每周看 10 分钟账单
用 Copilot 预览账单 或 Cursor Dashboard,回答三个问题:哪类任务最耗?是否模型选错?是否会话太长?没有观测就没有优化。
四、构建「省 Token」体系:个人 → 团队 → 组织
技巧散用,效果有限;体系才是把 Token ROI 稳住在高位的办法。建议分三层搭建。
4.1 个人层:Token 意识 + 任务模板
Token 意识不是数 Token,而是养成三个反射:
- 这任务该走 补全轨 还是 Agent 轨?
- 这一轮对话,Uncertainty 减少了多少?
- 若失败,最大损失是多少 Token(会话长度 × 模型档位)?
沉淀 1 页任务模板(可贴在笔记里),固定字段:
[轨道] 补全 / Agent
[模型档] 日常 / 复杂
[目标] 一句话
[边界] 不可改动的文件/接口
[验收] 1. 2. 3.
[输出] 先摘要 / 直接补丁 / 仅测试
[预算] 预计 1 轮 / 最多 3 轮,否则切片每次开 Agent 前填 30 秒,长期能砍掉大量无效轮次。
4.2 团队层:流程嵌入,而非口头提醒
| 机制 | 作用 |
PR 模板加 Acceptance Criteria | 减少 Agent 猜需求 |
| 限制「超大 AI PR」(如 >400 行须说明切片计划) | 抑制 Token 黑洞式改动 |
| 模型使用规范(日常 / 复杂 / 禁止) | 避免全员默认最贵模型 |
| Code Review Agent 白名单路径 | 控制 Review 双账单 |
| 周会 5 分钟「本周高消耗任务复盘」 | 找结构性浪费,不是追责个人 |
团队体系的核心:把省 Token 写成默认流程,而不是依赖个人自律。
举一个远程团队的典型场景:发布前夜,有人用 Agent 对全 monorepo 做「全面安全扫描」——单会话消耗大量 Credits,产出却是数百条低置信告警,Review 又触发 Actions 分钟。若有 Review 白名单 + 任务切片规范,同样目标可拆成「只扫 auth 模块 + 只输出 top 10 可验证项」,Token 与 CI 成本都可降一个数量级。体系的价值,就在于把这类决策从「个人临场判断」变成 默认规则。
4.3 组织层:FinOps 与工程治理对齐
企业有 Copilot Credits 池化 与 三级预算(enterprise / cost center / user)时,组织体系应包含:
- 基线:切换前用 30 天预览账单取 p50 / p95 / p99。
- 策略:补全全员;Agent 按角色 / 项目开预算;封顶 vs 加价续用写进政策。
- 归因:Showback 到团队(不必一开始到个人),识别 power user 是「真高产」还是「不会切片」。
- KPI 迁移:内部粗糙指标从「生成了多少行」转向 「每 $Credits 合并了多少 PR / 关闭了多少 incident」。
组织层立意:Token 预算是工程资源,不是行政部门单独背锅的数字。
对 power user 不要简单「封号」:先区分 高消耗高产(复杂域、合理切片)与 高消耗低产(整库 Agent、无验收反复试)。前者应保障配额;后者配 配额 + 复盘(任务是否该切片、是否该降模型档)。这与云 FinOps 里「优化实例规格」而非「一律关机」是同一逻辑。
flowchart TB
subgraph input [投入]
T[Token / Credits]
M[模型档位]
C[上下文规模]
end
subgraph process [过程]
S[任务切片]
A[验收标准]
R[轨道分流]
end
subgraph output [产出]
D[可合并交付]
V[可验证测试]
end
input --> process --> output
output --> ROI["Token ROI = 交付 / 投入"]五、拉高 Token 产出比:一个可操作的闭环
把上面散点收成 PDCA 闭环,每月迭代一次即可:
Plan(计划) 任务进 Agent 前:选轨道、选模型档、写验收、估轮次上限。
Do(执行) 按模板执行;超过轮次上限仍未收敛 → 强制切片或人工接手,不要「再试一轮」。
Check(检查) 本周合并的 PR 中,哪些经过 Agent?对应消耗档位?有无 返工 PR(合并后又 revert)——返工是 Token ROI 的负资产。
Act(改进) 把「高消耗 + 低交付」的任务类型记入 Avoid List(例如:无 spec 的全仓库重构);把「低消耗 + 高交付」的模式记入 Playbook(例如:单测补全 + 小范围 bugfix)。
个人用户没有企业 Dashboard 时,仍可用 代理指标:本周 Agent 会话数、平均轮次、合并 PR 数、revert 数。四个数摆在一起,Token ROI 高低一目了然——revert 是最诚实的账单。
三条硬纪律:
- 没有验收,不开 Agent。
- 没有切片,不跨模块。
- 没有复盘,不放大预算。
六、结语:省 Token 的本质,是省「无效不确定性」
「高级请求次数」的终结,表面是计费单位变了,实质是 AI 编程进入了资源约束时代。Cursor 与 Copilot 用同一套 Token 账本告诉开发者:你可以继续享受便宜的补全,但 每一次「让 AI 替你想清楚」都要付算力费。
因此,省 Token 的最高形态不是极简 prompt,而是 在开口之前,已经帮 AI 删掉了大部分无效不确定性——边界清楚、任务够小、验收可测、模型匹配、会话知止。
当同行还在比「谁的 Agent 跑得久」时,你比的是 「同等 Credits 下,谁合并得更多、返工更少」。这才是 Token 账本时代真正该卷的能力:不是生成更多代码,而是用更少的推理,换更多可验证的正确。
参考资料
- GitHub Blog, GitHub Copilot is moving to usage-based billing(2026-04-27).
- GitHub Docs, Usage-based billing for individuals.
- Cursor Blog, Clarifying our pricing(2025-07).
发表回复