
Visual Studio 是微软推出的一体化集成开发环境,一直被奉为“宇宙第一 IDE”。它集成了代码编辑、项目管理、编译构建、调试、测试、性能分析、部署等一整套能力,长期以来都是 C#、.NET、C++、桌面应用和企业级应用开发中的核心工具之一。相比于主要负责编辑代码的轻量工具,Visual Studio 更强调完整工程能力,尤其在调试、诊断和大型项目协作方面优势明显。
如果说调试的本质,是在系统行为偏离预期时重新恢复可解释性,那么 Visual Studio 调试器的价值,恰恰在于它把“观察运行时事实”这件事做得足够细,也足够系统。你不只是能看到某一行代码有没有执行,还能看到它是在什么调用路径下执行的、它执行时变量处于什么状态、异常是在哪里抛出的、某个条件究竟在第几次迭代时开始失真,甚至还能进一步判断这到底是逻辑问题、并发问题,还是性能问题。
这篇文章并不试图重复官方文档已经系统覆盖的功能清单,而是希望站在实际开发与问题排查的角度,对 Visual Studio 调试中最值得掌握的能力做一次有取舍的梳理。相比面面俱到地罗列功能,我更关心的是哪些能力在真实项目里最常用,哪些地方最容易踩坑,以及在官方说明之外,开发者真正需要积累的调试经验与判断方法。
Visual Studio 调试的学习资料
说到学习资料,最好的无疑是官方文档,这里完全没有必要做无谓的搬运工作。
- 调试文档的首页(从侧边栏足以看出 VS 调试功能的强大):调试器文档 – Visual Studio (Windows) | Microsoft Learn
- 以 C++ 为例,想了解大致的调试过程,可以参考:教程:调试C++代码 – Visual Studio (Windows) | Microsoft Learn
- 当前的开发自然离不开 AI,契合最好的必然是自家的 Github Copilot:使用 GitHub Copilot 进行调试 – Visual Studio (Windows) | Microsoft Learn
文档更重要的是查漏补缺,首先要知道有这个东西,其次在需要时还能找到它。
一、先建立一个正确预期:调试不是点几个按钮,而是组织证据
很多人第一次学 IDE 调试时,容易把它理解成一组零散功能:断点、单步、看变量、继续执行。实际上,这些能力只有放进一个明确的排查流程里才有意义。比较稳健的调试路径通常是这样的:
- 先复现问题,确认问题真的存在,而且尽量能稳定触发。
- 再决定从哪里观察,选择断点、异常中断、日志点或附加调试。
- 观察运行时证据,看变量、调用栈、线程状态和异常信息。
- 根据证据提出假设,再设计下一轮验证。
- 修复后重新验证,确认改动解决的是根因而不是表象。
Visual Studio 的调试器之所以强,不是因为它能替你思考,而是因为它让上面这条链路里每一个环节都有更合适的工具可用。下面的内容,可以理解成对这条链路的具体展开。
二、开始调试之前:先把启动方式和环境搞清楚
很多调试低效,并不是因为不会看变量,而是从一开始就没有在正确的环境里观察问题。
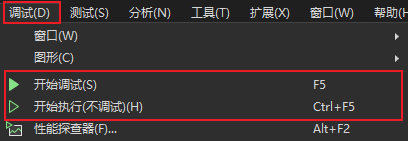
1. F5 与 Ctrl+F5 的区别
这是最基础,但也最容易被忽略的区别。
- `F5` 是“开始调试”,程序会在调试器附加的状态下运行。
- `Ctrl+F5` 是“不调试直接运行”,适合快速验证功能,但不会进入断点调试流程。
如果你想查看变量、调用栈、异常详情,或者让程序在断点处暂停,就必须用 `F5`。
2. Debug 配置和 Release 配置不要混用理解
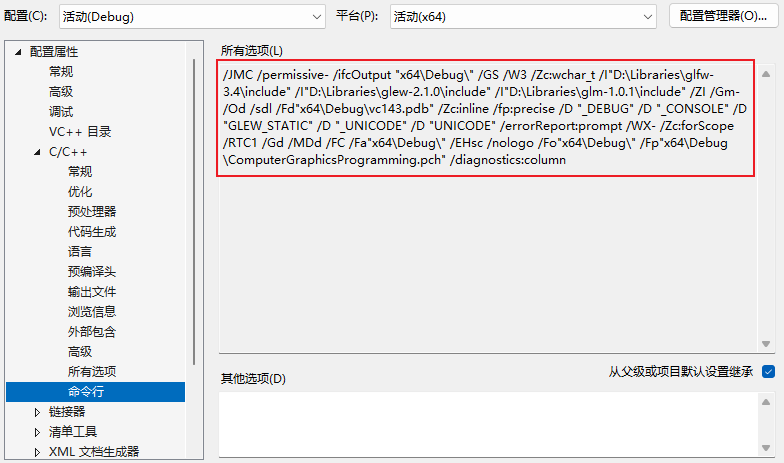
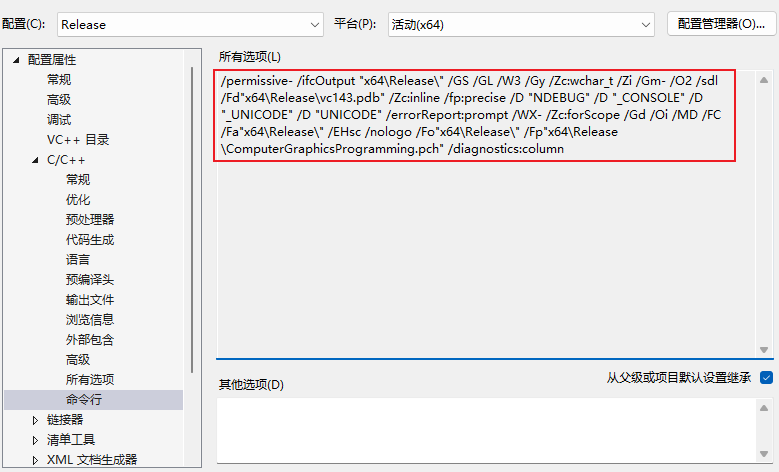
不少问题之所以难查,是因为开发者在 Debug 环境里看不到问题,却默认线上一定也一样。实际上,Debug 和 Release 的编译方式、优化策略、符号信息都可能不同,表现出来的运行行为也可能不同。尤其在以下场景里,这个差异非常明显:
- 编译优化导致变量显示异常或执行顺序不易直观理解。
- 多线程与竞态问题只在更接近真实负载时暴露。
- 某些仅在 Release 配置下才触发的边界行为。
因此,开始排查之前要先问自己:我当前调试的,是否就是问题真实发生的配置和启动方式?如果不是,后面越看越细,结论也可能越偏。
注:Debug 和 Release 本质上是两套不同的编译参数集合,它们的目标、优化策略和生成产物都有显著差异。这不仅仅是一两个参数的差别,而是一套完整的、为不同目的设计的配置组合。
3. 启动参数、环境变量和启动项目同样属于调试上下文
Visual Studio 中很多项目类型都可以在项目属性或启动配置里设置:
- 启动参数
- 工作目录
- 环境变量
- 启动浏览器或特定 URL
- 多项目联合启动
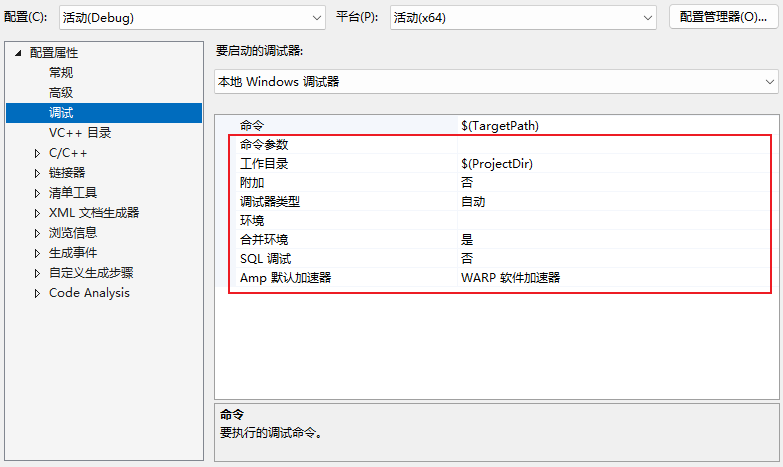
这类配置很容易被忽略,但它们往往直接决定“为什么你这里复现不了,别人那里却能复现”。如果问题和输入、配置、路径、网络地址、端口、账户权限有关,那么这些启动上下文必须先校准。
4. Restart 比 Stop 再重启更高效
很多开发者调试时一旦改了条件,就顺手 Stop,再 F5 重新启动。Visual Studio 的 Restart 可以节省一段时间,特别是在启动成本较高的应用里更明显。它不改变排查逻辑,但能显著降低你重复验证的摩擦成本。
三、断点:调试最基本,也最容易被低估的能力
断点不是“让程序停住”这么简单,它的意义是把观察行为放到正确的位置上。
1. 普通断点:先回答“代码到底有没有走到这里”
这是最基础的用法,也是排查时最先要确认的问题之一。很多 bug 看起来像“这一行有问题”,但真正的问题可能是:这一行根本没有执行。
适合普通断点的典型场景:
– 怀疑某个分支没有进入。
– 怀疑某个方法根本没有被调用。
– 想确认执行流到达某个关键节点之前,状态是否已经异常。
如果连代码是否执行到这里都不确定,不要急着猜逻辑,先让程序停下来。
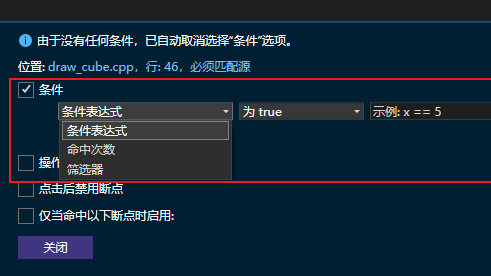
2. 条件断点:当问题只在特定状态下发生时
条件断点是 Visual Studio 里最值得熟练掌握的功能之一。它的核心价值是:不是每次走到这里都停,而是只有满足指定条件时才停。
典型场景包括:
- 某个变量等于特定值时才出错。
- 某个对象状态发生变化后才开始异常。
- 只想在某个请求、某个线程、某个流程分支下暂停。
实际排查中,条件断点能避免你在循环、热点路径、频繁调用的方法上被大量无关暂停打断。如果一个问题只在“第 500 次迭代后”或者“某个用户输入触发时”才出现,条件断点通常比反复按 `F5` 高效得多。
3. Hit Count:循环问题和时序问题的利器
命中次数断点特别适合这类问题:前几次都正常,到了某一次之后状态开始漂移。比如:
- 某个循环在特定轮次后结果不对。
- 某个消息处理函数在重复调用后状态污染。
- 某个缓存、集合或计数器在累计一段时间后才出错。
这时候,与其一次次继续运行,不如直接让断点在指定命中次数上暂停。
4. Filter:多线程、多进程问题不要所有上下文一起看
断点筛选器允许你把中断范围缩小到特定进程、线程、机器等条件。只要问题带有并发、后台任务、多个工作线程或多实例进程特征,这个能力就很有价值。
否则你会遇到一个非常典型的调试噪声:断点确实命中了,但命中的并不是你想看的那个执行上下文。
5. Function Breakpoint:知道函数名,不知道位置时非常好用
大型项目里,函数可能被重载、被跨文件调用,或者你只知道方法名,不想逐个翻源文件。这种情况下,函数断点比手工找位置更有效。
它尤其适合:
- 排查框架回调、生命周期方法、事件处理函数。
- 怀疑某个公共方法被异常频繁调用。
- 代码位置不固定,但调用入口相对明确。
6. Tracepoint:想观察事实,但不想暂停程序
Tracepoint 可以理解成“不会中断执行的断点”。命中后它会往输出窗口打印信息,而不是像普通断点那样让程序停住。
它非常适合以下场景:
- 问题出现在高频路径,普通断点会严重打断流程。
- 你需要记录多个变量的变化趋势,而不是停在每一个节点。
- 你暂时不想改代码加日志,但想得到类似日志的效果。
很多人遇到这种场景的第一反应是改代码插日志。Tracepoint 的价值就在于,它让你在不修改业务代码的前提下获得临时观察能力。
7. Data Breakpoint:当你关心的是“谁改了这个值”
这是非常强的一类能力。普通断点回答的是“代码执行到哪里”,数据断点回答的是“这个值到底是谁改的”。
典型场景:
- 某个属性莫名其妙被改掉了。
- 某个对象状态在某一时刻被污染,但你不知道写入点在哪。
- 某个值在大量调用链中被多处共享和修改。
不过它并不是无条件可用。某些托管数据断点依赖特定 .NET 版本和对象形态,原生环境下也会受到硬件断点数量限制。也就是说,它非常强,但用之前要先确认当前项目类型和运行时是否支持。
8. Dependent Breakpoint:只在前置条件成立后再启用
依赖断点适合复杂路径定位。比如一个公共工具函数被全项目很多地方调用,你只对“它在某条特定业务链路中被调用”感兴趣。这时候直接给工具函数打断点会被大量无关命中淹没,而依赖断点可以让你先命中上游断点,再有条件地打开下游断点。
它本质上是在调试器层面表达“这个点只有在另一个前提成立后才值得观察”。
四、单步执行:不是为了慢,而是为了确认因果顺序
很多初学者把单步调试看成“手动慢放程序”。这个理解不完全错,但太浅了。单步执行真正的价值是确认执行顺序和状态变化的因果关系。
1. Step Into:你怀疑问题在被调用的方法内部
当一行代码包含方法调用,而你怀疑真正的错误发生在调用进去之后,使用 Step Into 最合适。它会进入方法体内部,让你继续观察更细的执行路径。
适用场景:
- 你不信任被调用方法的内部逻辑。
- 你怀疑输入参数没问题,但方法内部改坏了状态。
- 你要追踪一条跨多层封装的执行链。
2. Step Over:你知道这行会执行,但暂时不关心内部细节
很多时候,你不是要把每一个方法都钻进去看,而是要快速推进到更关键的地方。这时 Step Over 更高效。
一个成熟的调试习惯不是“逢调用必进”,而是知道哪些地方值得深挖,哪些地方先跳过。否则你会在无关细节里消耗大量注意力。
3. Step Out:当前方法已经看够了
如果你已经进入了一个方法,但观察后判断问题不在这里,就没必要再一行行往下走。Step Out 可以直接执行到当前方法返回,把你带回上层调用点。
这类操作的意义在于节省认知成本。调试效率不只是工具熟不熟,更是你是否愿意及时退出错误路径。
4. Run to Cursor 和 Run to Click:临时断点,比正式断点更灵活
有时你只想快速跑到当前可见区域的某一行,并不想真的设一个长期断点。Run to Cursor 和 Run to Click 就很适合这种临时导航。
典型场景:
- 你已经确认前面几段逻辑没问题,想直接推进到后面一段。
- 你临时需要跳过一些重复路径。
- 你想观察当前位置之后的一次性行为,但不想污染断点列表。
五、看变量只是开始,更关键的是看“变量在什么上下文里成立”
很多人调试时只盯着一个变量值对不对,但实际上单个值的意义通常依赖上下文。Visual Studio 提供的变量观察能力,核心不是“让你看到值”,而是让你把值放回运行时环境里理解。
1. Data Tips:最快速的局部确认
暂停在断点时,把鼠标悬停到变量上,就能看到当前值。这是最轻量的观察方式,适合回答一些局部问题:
- 这里这个参数到底是不是 `null`?
- 这个集合现在有几个元素?
- 这个对象当前的关键属性是什么?
如果你只是想快速确认一两个值,Data Tips 往往比切换窗口更直接。
2. Autos 和 Locals:当前作用域的状态快照
这两个窗口非常适合做“当前现场扫描”。
- Autos 更偏当前语句附近相关变量。
- Locals 更偏当前作用域中可见的变量集合。
它们的价值在于让你从局部变量出发,快速建立“这一步运行时到底处于什么状态”的整体印象,而不是只看一个单独表达式。
3. Watch:把真正关键的变量长期盯住
当你排查的问题跨多个步骤、多个方法、多个断点时,Watch 会比反复悬停看值稳定得多。它适合:
- 追踪某个关键变量或表达式的变化。
- 对比修复前后同一表达式的状态。
- 长时间盯住某个集合大小、标志位、对象属性。
成熟一点的做法不是把所有变量都丢进 Watch,而是只放那些真正能验证你当前假设的表达式。否则 Watch 也会变成噪声源。
4. QuickWatch 和即时求值:验证一个小假设
有时你不只是想看值,还想临时算一个表达式、展开一个对象、检查某个条件是不是成立。QuickWatch 和 Immediate Window 就适合这种“边看边验”的场景。
例如:
- 验证某个集合筛选条件下的结果数量。
- 临时检查某个字符串处理结果。
- 确认一个布尔条件到底为什么没有满足。
它们的意义不是替代代码,而是在不改业务逻辑的前提下做一轮轻量实验。
六、调用栈:很多 bug 不在当前行,而在你是怎么走到当前行的
如果让我在“只会看变量”和“会看调用栈”的开发者之间做区分,我会认为后者通常更接近真正会调试。
因为很多问题不是“这一行写错了”,而是“这一行在错误的调用路径里被执行了”。
1. 调用栈回答的是“你为什么会到这里”
当程序停在某一行时,Call Stack 能告诉你:
- 当前函数是谁调用的。
- 上层是谁再调用的。
- 整条调用链是如何层层进入当前上下文的。
这在以下场景里非常关键:
- 某个公共方法被多个入口调用,你需要知道本次到底来自哪条链路。
- 某个参数值不对,但当前方法只是被动接收者。
- 某个异常在这里爆出,但根因可能发生在更早的上游调用里。
2. 栈顶不等于根因
这是非常常见的误区。异常停下来的那一行,往往只是“症状最先爆出来的位置”,不一定就是“污染最早发生的位置”。
例如:
- 在这里空指针了,不代表 `null` 是在这里产生的。
- 在这里越界了,不代表集合是在这里被错误构造的。
- 在这里转换失败了,不代表原始数据是在这里变脏的。
因此,看调用栈的意义,就是把当前断点从一个孤立点,扩展成一个有来路的执行路径。
七、异常调试:不要只看报错信息,要看异常为什么在这里出现
Visual Studio 的 Exception Helper 对很多 .NET 开发者来说都是高频工具,但很多人只把它当作“报错提示框”。实际上,它能提供更清晰的异常类型、消息、上下文和中断策略。
1. 先分清是抛出点,还是最终冒泡点
一个异常可能在底层抛出,在上层才真正被你注意到。调试时要先分清:当前停下来的位置,是第一现场,还是已经经过多层传播之后的结果。
2. 配置 Exception Settings 很重要
很多问题之所以定位慢,是因为开发者只在程序最终崩掉时才看见异常。实际上,Visual Studio 允许你配置某些异常在抛出时就中断,而不是等它一路被吞掉、包装、重抛,最后只剩下一个不够清晰的外层错误。
这类设置尤其适合:
- 频繁被捕获但最终行为异常的业务代码。
- 被框架包装后原始信息不易直接判断的异常。
- 需要尽量靠近异常源头观察上下文的场景。
3. 例外情况:不是所有异常都值得“抛出即中断”
有些框架和运行库会大量使用内部异常流程控制。如果你把所有异常都配置成抛出即中断,很可能会被无意义噪声打爆。因此,异常设置一定要服务于当前排查目标,而不是越敏感越好。
八、Attach to Process:不是所有问题都能从“自己启动程序”开始
很多教程都默认你是从 IDE 里直接 F5 启动应用,但现实里并不总是这样。
有些问题出现在:
- 已经运行中的桌面程序
- IIS 或后台服务托管的进程
- 外部启动的工具链、子进程或宿主进程
- 本机以外的目标环境
这时候你就需要 Attach to Process。
1. 什么时候应该用附加调试
当问题与启动时机无关,而与进程当前状态、宿主环境、真实交互过程更相关时,附加调试通常比从零启动更贴近现场。
例如:
- 只在运行一段时间后才出现内存或状态问题。
- 某个问题依赖外部系统触发,无法轻易用本地启动流程复刻。
- 程序必须在真实宿主中运行,单独启动没有意义。
2. 附加调试最常见的坑
- 附加到了错误的进程。
- 代码版本与符号文件不匹配。
- 调试类型没有选对,导致断点不命中或变量显示异常。
- 权限不足,无法正常附加。
如果你发现断点打上去是空心的、始终不命中,或者变量信息异常缺失,先别急着怀疑代码,优先检查进程、符号和调试类型。
九、远程调试:当问题只出现在“你的机器之外”
很多问题本质上不是逻辑复杂,而是环境相关。比如:
- 只在测试机或服务器出现。
- 只在特定权限、特定网络、特定依赖版本下出现。
- 本地无法稳定复现,但远程环境能稳定复现。
这类问题如果一直坚持“先在我电脑上复现”,往往只会卡住。远程调试的意义,是把调试器带到更接近真实问题的环境里。
当然,远程调试通常也意味着更高的使用门槛:
- 远程调试器部署和连接配置
- 网络和权限限制
- 目标机器与本地代码/符号一致性
- 对线上环境影响的控制
它不是日常首选手段,但在环境差异型问题里非常关键。
十、线程、任务与并发问题:只盯一条执行流,常常看不到真相
如果你的程序涉及异步、任务调度、后台线程、并发访问,那么很多“偶发 bug”其实都不可能只靠单线程视角看清楚。
Visual Studio 在这类场景下的关键价值,不只是能暂停程序,而是能帮助你识别不同执行流之间的关系。
1. 什么时候该切到线程或任务视角
出现以下特征时,就应该提高对线程与任务窗口的使用频率:
- 问题偶发,且难以稳定复现。
- 同一段逻辑在不同线程上表现不一致。
- UI 卡死、后台任务不返回、等待链异常。
- 共享状态偶尔被污染。
2. 常见并发问题的调试思路
这类问题通常不要上来就盯着某一行,而要先回答:
- 当前断点发生在哪个线程上?
- 还有哪些线程在同时运行或等待?
- 当前变量异常,是本线程写坏的,还是其他执行流改坏的?
- 调用栈显示的等待关系是否合理?
换句话说,并发问题不是“不好打断点”,而是“只打普通断点往往不够”。
十一、Hot Reload 与 Edit and Continue:提高验证速度,但不要把它当成万能修复器
Visual Studio 支持在调试过程中修改部分代码并继续运行,这对缩短验证闭环非常有帮助。尤其在启动成本高、界面操作重、状态复现昂贵的程序里,Hot Reload 或 Edit and Continue 可以明显提高效率。
适合它的场景:
- 小范围逻辑修正
- 文本、显示、简单分支调整
- 需要快速验证某个想法是否有效
但它不适合被误用成“边改边赌”的方式。调试中的代码修改只是为了更快验证假设,不是为了跳过严谨的修复流程。真正需要提交的修复,仍然应该回到正常开发、构建和测试链路里确认。
十二、Diagnostic Tools 与性能分析:不是所有 bug 都会直接报错
很多人把调试等同于“找异常、看变量、修逻辑”。但现实里相当一部分问题根本不以报错形式出现,而是表现为:
- 程序越来越慢
- 内存持续上涨
- 某个操作卡顿严重
- 界面冻结但没有明显异常
这类问题仅靠交互式断点调试通常不够,因为你关注的不是某一行是否执行,而是系统在一段时间内的资源使用和热点分布。
1. 什么时候该从断点调试切换到性能诊断
如果你的问题是:
- “为什么这里慢?”
- “为什么内存不释放?”
- “为什么这个页面打开越来越卡?”
那就应该尽早考虑 Diagnostic Tools、CPU 使用分析、内存分析等工具,而不是还停留在每次打断点看变量。
2. 性能问题的一个常见误区
很多开发者会把“程序没崩”理解成“逻辑大致没问题”。其实性能退化、资源泄漏、频繁 GC、阻塞等待,本质上同样是运行时行为偏离预期。只不过它们不是以异常形式爆出来,而是以时间和资源的方式表现出来。
十三、企业版或特定场景能力:很强,但不要写成默认可用
Visual Studio 里还有一些很强的高级能力,比如快照调试、历史状态回看、某些企业级线上诊断能力。它们在合适场景下非常有价值,尤其适合处理线上难复现问题,但使用时必须明确前提:
- 有些能力依赖 Visual Studio Enterprise。
- 有些能力依赖特定部署环境,比如 Azure 场景。
- 有些能力依赖项目类型、运行时或额外配置。
写调试文章时,最容易误导读者的地方,就是把这类功能与高频基础能力混在一起,仿佛人人默认都能用。更稳妥的写法应该是:把它们归入“进阶与特定场景工具”,并明确适用边界。
十四、把这些工具串起来:一条更像工程实践的排查路径
上面这些功能如果只是分散记忆,实际用起来仍然容易乱。更有效的方式,是把它们放进一条排查主线里。
下面给一个更接近真实项目的使用顺序。
第一步:先稳定复现,不要一开始就盲目深入
确认问题发生在什么配置、什么输入、什么操作路径下。需要的话先校准:
- 启动项目
- 参数和环境变量
- Debug/Release 配置
- 数据源和外部依赖
- 操作路径
如果问题都复现不稳定,后面的调试就很容易变成随机试错。
第二步:先用最便宜的观察手段判断范围
从最基础的问题开始确认:
- 代码有没有走到这里?
- 这个分支有没有进入?
- 异常是不是在这里第一次抛出?
这个阶段通常用普通断点、异常设置、调用栈和少量 Data Tips 就够了。目标不是立刻找到根因,而是快速缩小范围。
第三步:当范围缩小后,升级观察精度
如果问题只在某个值、某个对象、某个轮次、某个线程下发生,就不要再用普通断点硬扛,而应切换到:
- 条件断点
- Hit Count
- Filter
- Watch
- Tracepoint
- 数据断点
这是很多开发者效率拉开差距的地方。会不会调试,往往就体现在你是否知道什么时候该从“粗观察”切换到“精观察”。
第四步:确认当前停下来的地方是不是根因
这一步一定要看调用栈。很多修复失败,都是因为开发者在“第一个看到异常的地方”动手,却没有追溯到“第一个把状态搞错的地方”。
如果你发现当前点更像症状而不是源头,就继续顺着调用栈往上看,必要时重新布置断点位置。
第五步:问题如果与环境、宿主或运行时过程有关,就换调试方式
不要执着于一定要从本地 F5 开始。只要问题更贴近真实进程或远端环境,就应该考虑:
- Attach to Process
- 远程调试
- 更接近真实配置的启动方式
第六步:如果问题表现为慢、卡、涨,而不是错,就不要再只盯逻辑断点
这时候你要换工具,而不是换猜法。进入 Diagnostic Tools、CPU 分析、内存分析,往往比再加十个断点更有效。
十五、常见低效调试习惯
工具再强,如果使用方式不对,仍然会陷入低效。下面这些问题非常常见。
1. 断点打得很多,但没有明确假设
如果你只是“这里停一下、那里停一下”,却没有要验证的判断,调试就会变成低质量漫游。断点不是装饰,应该服务于某个明确问题。
2. 只看当前变量,不看调用栈
这会导致你总是在处理表象,尤其容易在空指针、越界、状态污染类问题上误判根因。
3. 一上来就改代码加日志
日志当然很重要,但不是所有问题都值得先改代码。很多局部问题,用断点、Watch、Tracepoint 或 Immediate Window 先观察,成本更低,也更快。
4. 在错误的环境里认真调试
如果线上出问题,你在本地默认配置里看半天,最后得到的可能只是一个无关结论。环境不对,调试越努力,偏差可能越大。
5. 修复后没有重新验证完整路径
修复一个表现,不等于解决根因。真正完成一次调试,至少要确认三件事:
- 原问题消失了。
- 触发问题的根因被处理了。
- 修复没有引入新的副作用。
十六、给不同阶段开发者的一个实用建议
如果你是初学者,先把下面几项用熟:
- 普通断点
- 条件断点
- Step Into / Step Over / Step Out
- Data Tips
- Locals / Watch
- Call Stack
- 异常中断设置
这几项已经足够让你解决大量日常问题。
如果你已经有一定经验,下一步值得重点补齐的是:
- Tracepoint
- 数据断点
- Attach to Process
- 远程调试
- 线程与任务视角
- Diagnostic Tools 与性能分析
因为真正让调试难度陡增的,通常不是基础语法错误,而是复杂上下文、真实环境和系统行为问题。
结语:Visual Studio 调试器的价值,不在于“功能多”,而在于它能帮你缩小不确定性
写到最后,会发现 Visual Studio 调试器并不是一堆分散的按钮集合,而是一整套“如何在运行时采集证据”的工具系统。断点负责控制观察时机,单步负责确认执行顺序,变量窗口负责理解当前状态,调用栈负责还原来路,异常助手帮助你贴近故障现场,附加调试和远程调试让你接近真实环境,性能工具则提醒你:不是所有 bug 都会以红字报错的形式出现。
真正重要的,不是你能不能把这些窗口都点开,而是你能不能在面对问题时知道下一步该看什么、为什么看、看完之后又该如何缩小范围。工具只是手段,调试效率最终仍然取决于你是否能把混乱现象还原成清晰因果。
如果把调试理解成“恢复系统可解释性”的过程,那么 Visual Studio 提供的这些能力,正是这套过程最直接的落点。会用它们,不只是为了更快修一个 bug,也是为了把自己从“靠经验猜”提升到“靠证据判断”。
发表回复